�������� | ������

����ԭ�����Լ���Ƶ�Iluminado��Ŀ�ķ���
����2019������������֯���ƣ�ȫ����Լ22�������ϰ��ߣ�����������10���˱�����Ԥ�����������ơ����۲�����������ԣ�ȫ��������������ս������Ԥ�������ƺͿ�������ĸ������������ƽ�ȡ�ȱ��ѵ�����ص��۲�������Ա���۲�������������Ҫ����ϵͳ������Ҳ�ܲ�ҵ�Ŀ���Ǽ������ǵ��ж�����ͬӦ����Щ��ս��������չʾ����Ŀ����Ŀǰ���ڽ��е����ݿ�ѧ������ĿIluminado��һ���֡�
����Capstone��Ŀ�����Ŀ��
�����Ҵ���������Ŀ��Ŀ������ѵ��һ�����ѧϰ����ģ�ͣ�����ʵ�ָ�ģ�Ͷ��ڵ������ͥ��˵�dz�����ã����ҿ����Եͳɱ�ִ�г�ʼ����������ϡ�ͨ��ʹ���ҵ�ģ�ͳ����ۿ�ҽ���Ϳ��Ը�������Ĥ�۵���Ӱȷ���Ƿ���Ҫ�������и�Ԥ��
������Ŀ���ݼ���Դ
����OphthAI�ṩ��һ����Ϊ����Ĥ�۵༲��ͼ�����ݼ�(Retinal Fundus Multi-Disease Image Dataset�����“RFMiD”)�Ĺ�������ͼ�����ݼ��������ݼ�����3200���۵�ͼ����Щͼ������̨��ͬ���۵�������㣬����������������Ĥר�Ҹ����Ѳþ��Ĺ�ʶ����ע�͡�
������Щͼ���Ǵ�2009-2010���ڼ���е���ǧ�μ������ȡ�ģ���ѡ����һЩ��������ͼ��Ҳ�������ٵ�������ͼ�Ӷ�ʹ���ݼ�������ս�ԡ�
�������ݼ�����Ϊ�������֣�����ѵ����(60%��1920��ͼ��)��������(20%��640��ͼ��)�Ͳ��Լ�(20%��640��)��ƽ�����ԣ�ѵ�������������Ͳ��Լ��еĻ��м�����ռ�ȷֱ�Ϊ60±7%��20±7%��20±5%�������ݼ��Ļ���Ŀ���ǽ���ճ��ٴ�ʵ���г��ֵĸ����۲���������ȷ����45�༲��/��������Щ��ǩ���Էֱ�������CSV�ļ����ҵ���������RFMiD_Training_Labels.CSV��RFMiD_Validation_Labels.SSV��RFMiD_Testing_Labels.CSV��
����ͼ����Դ
������������ͼ����һ�ֱ���Ϊ�۵�������Ĺ�������ġ��۵��������һ��ר�ŵĵͱ�������������һ̨����������ϣ����������۵ף����۾�������Ĥ�㡣
�������ڣ�������۵�����������ֳ�ʽ�ģ���˻���ֻ��ֱ�Ӿ�ͷ�����У����������ⲿ�ֱ�ʾ�������۵�ͼ��
�����ֳ�������������ŵ�ģ���Ϊ���ǿ��Ա�Я������ͬ��λ�ã����ҿ�����������������Ļ��ߣ���������ʹ���ߡ����⣬�κν��ܹ�������ѵ��Ա�������Բ�������ͷ���Ӷ��ܹ�ʹ����ˮƽ���µĵ������߿��Կ��١���ȫ����Ч�ؽ�����ȼ�顣
�����۵�����Ĥ����ϵͳ���������
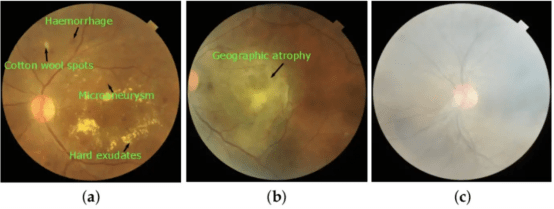
�������ڸ����Ӿ����������ͼ��(a)��������Ĥ����(DR)��(b)�����Իư߱���(ARMD)��(c)�ж���(MH)��
��������������������?
���������ɸ����̿���ͨ�����ѧϰ��������������������ۿ�ҽ��ʹ����϶�Ƽ����С�
������һ����Ҳ����Ϊ����������ϣ����漰�Ի�ϸ���ļ�顣ҽ�����Խ���������飬��ȷ�����˵��۾��Ƿ�����κ��쳣��
�������ѧϰ������Ĥͼ������е�Ӧ��
�����봫ͳ�Ļ���ѧϰ�㷨��ͬ����Ⱦ���������(CNN)����ʹ�ö��ģ�͵İ취ʵ�ִ�ԭʼ�������Զ���ȡ�ͷ���������
���������ѧ���緢���˴������£������й�ʹ�þ���������(CNN)��ʶ������۲������ģ�����������Ĥ����ͽ���쳣(AUROC>0.9)������۵ȡ�
��������ָ��
����AUROC������ROC������Ϊһ�����֣�������������ģ����ͬʱ���������ֵʱ�����ܡ�ֵ��ע����ǣ�AUROC����Ϊ1������һ�������ķ�������AUROC�÷�Ϊ0.5��Ӧ������²⡣
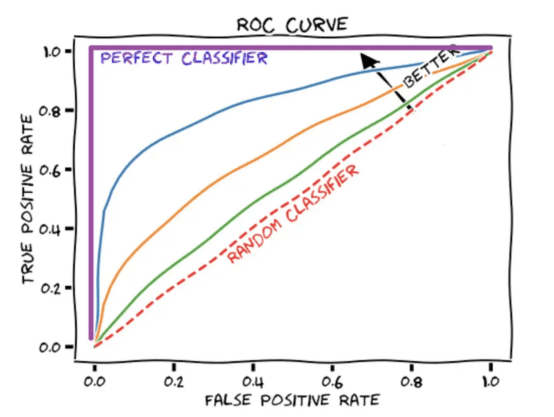
����ROC����ʾ��ͼչʾ
�������÷���——��������ʧ����
����������ͨ���ڻ���ѧϰ��������ʧ����������������Ϣ���������һ�ֶ��������������ض���Ļ����ϣ�ͨ�����ڼ����������ʷֲ�֮��IJ��죬�������ؿ��Ա���Ϊ�Ǽ��������ֲ�֮������ء�
����������Ҳ������ʧ�йأ���Ϊ������ʧ�����������ֶ����������Բ�ͬ����Դ��������������ģ�͵���ʧ����ʱ�������ְ취�����������ͬ�����Ի���ʹ�á�
����(�йؾ������飬��ο���https://machinelearningmastery.com/logistic-regression-with-maximum-likelihood-estimation/)
����ʲô�ǽ�����?
�����������Ǹ�������������¼������������ʷֲ�֮�����Ķ����������ܻ��ǵã���Ϣ�����˱���ʹ����¼������λ���������¼����������������Ϣ�����߸����¼���������ٵ���Ϣ��
��������Ϣ���У�����ϲ�������¼���“����”���¼������Ŀ�����ԽС����Խ���˾��ȣ�����ζ���������˸������Ϣ��
���������¼�(���˾���)��������Ϣ��
�����߸����¼�(����Ϊ��)����Ϣ���١�
�����ڸ����¼�P(x)�ĸ��ʵ�����£��Ϳ���Ϊ�¼�x������Ϣh(x)��������ʾ��
��������
����h(x) = -log(P(x))
����ͼ4�������IJ�ͼ(ͼƬ��Դ��Vlastimil Martinek)
�������ǴӸ��ʷֲ��д������ѡ����¼�����ı�������ƫ̬�ֲ����нϵ͵��أ����¼�������ȸ��ʵķֲ�һ����нϴ���ء�
����Ŀ����Ԥ�����֮�ȵ�����˵��(ͼƬ��Դ��Vlastimil Martinek)
����ƫ̬���ʷֲ����н��ٵ�“����”��������Ҳ���нϵ͵��أ���Ϊ���ܵ��¼�ռ������λ�������˵��ƽ��ֲ������˾��ȣ������ظ��ߣ���Ϊ�¼������Ŀ�������ͬ��
����ƫ̬���ʷֲ�(����Ϊ��)�����ء�
����ƽ����ʷֲ�(���˾���)�����ء�
������H(x)������Ծ���x����ɢ״̬�е�һ��x����������������P(x)���㣬����ͼ��ʾ��
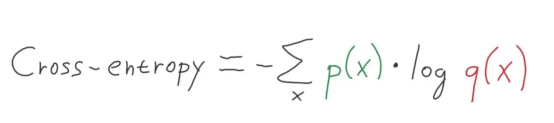
�����༶�����ع�ʽ(ͼƬ��Դ��Vlastimil Martinek)
������������——����ʹ�ö���ཻ����——���ڽ����ص�һ�־���Ӧ�����Σ����е�Ŀ����õ��ǵ��ȱ�������������(����Ȥ�Ķ��߿ɲο�Vlastimil Martinek������)
������ʧֵ�������ֽ�ͼ1(ͼƬ��Դ��Vlastimil Martinek)
������ʧֵ�������ֽ�ͼ2(ͼƬ��Դ��Vlastimil Martinek)
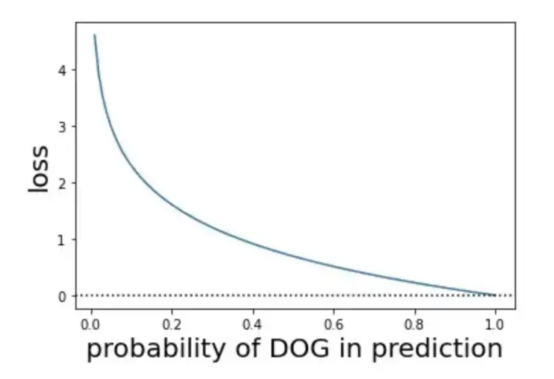
�������ڸ��ʺ���ʧ�Ŀ��ӻ�չʾ(ͼƬ��Դ��Vlastimil Martinek)
������Ԫ��������ô��?
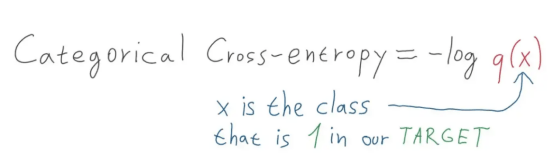
�������ཻ���ع�ʽͼ��(ͼƬ��Դ��Vlastimil Martinek)
���������ǵ���Ŀ��ѡ��ʹ���˶�Ԫ����——��Ԫ�����ط�������Ŀ��Ϊ0��1�Ľ����ط�����������ǽ�Ŀ��ֱ�ת��Ϊ[0,1]��[1,0]���ȱ���������ʽ������Ԥ�⣬��ô���ǾͿ���ʹ�ý����ع�ʽ�����м��㡣

������Ԫ�����ؼ��㹫ʽͼ��(ͼƬ��Դ��Vlastimil Martinek)
����ʹ�÷ǶԳ���ʧ�㷨������ƽ������
������һ�����͵Ķ��ǩģ�ͻ����У����ݼ����������ܴ��ڲ��ɱ�������������ǩ����ǩ���������ʱ�����ݼ������ڸ���ǩ���������ƶ����Ż����̾���������Ӱ�죬�����յ�������ǩ���ݶ�ǿ�����㣬�Ӷ�����Ԥ������ȷ�ԡ�
������Ҳ�����ҵ�ǰѡ�õ����ݼ������ٵ������
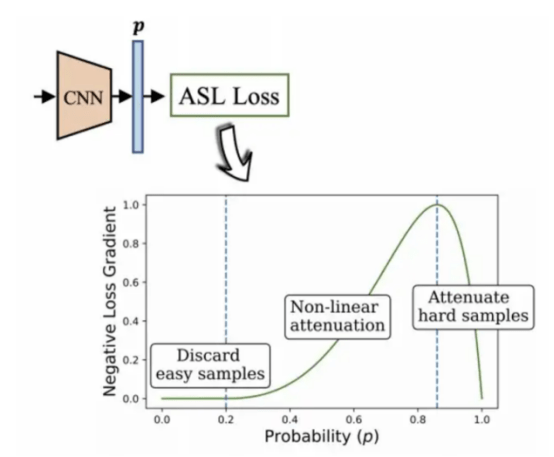
����������Ŀ�в�����BenBaruch���˿����ķǶԳ���ʧ�㷨(�ο�ͼ12)������һ�ֽ�����ǩ����ķ������������е����Ҳ�������ز�ƽ��ֲ����Ρ�
�������뵽�İ취�ǣ�ͨ�����ԳƵ��Ľ������е������������Ӷ����ٸ���ǩ���ֵ�Ȩ�أ�����ʵ��ͻ����������������Ϊ���ѵ�����ǩ���ֵ�Ȩ�ء�
�����ǶԳƶ��ǩ�����㷨(2020�����ߣ�Ben-Baruch��)
���������Ե���ϵ�ܹ�
�����������һ�£�������Ŀʹ������ͼ��ʾ����ϵ�ܹ���
����(ͼƬ��Դ��Sixu)
���������ܹ������õĹؼ��㷨��Ҫ������
����DenseNet-121
����InceptionV3
����Xception
����MobileNetV2
����VGG16
�������⣬�����й��㷨�й�����һ����������ɱ���Capstone��Ŀ����Ը���!����Ȥ�Ķ��߾����ڴ�!
�������߽���
���������ң�51CTO�����༭��51CTOר�Ҳ��͡���ʦ��Ϋ��һ����У�������ʦ�����ɱ�̽��ϱ�һö��
����ԭ�ı��⣺Deep Ensemble Learning for Retinal Image Classification (CNN)�����ߣ�Cathy Kam
�����������ݽ����Ķ���������Ͷ�ʽ��飬������Դ���Ͷ���߾ݴ˲����������Ե���


���գ���ζѼ���� "19 �꣬�����ഺ " Ϊ���������⣬�Ƴ���ȫ�� " ����˺����֬����Ƭ "������һϵ�о��ʻ��ּ��Ϊ�����ߴ���ǰ��δ�е�ζ�پ�ϲ�Ϳ������顣

���գ��й��ҵ缰���ѵ��Ӳ�����(AWE 2024)¡�ؿ�Ļ��ȫ�����ȵ������ն���ҵTCLʵҵЯ���¼�������Ʒ���࣬�Ը�Ϊ�����´�������������ն������AWE 2024��������

����ǰ��Ҫȥ���ڰ죬һ������������Ҫ������ˣ����ڷ������!�������칫������С��������ʾ�����ύ��ز��ϣ��������ӣ�����������ij���˻��ʹ����21600Ԫ��

2024��3��12�գ��ɰ������ٰ������Ϊ������4K �ӽ���¡���Ʒ���������Ϻ�ʢ����С�

�������˹����ܴ����ί�ᡢ�Ϻ��о���ί��������������ٸ���Ƭ����ί�Ṳָͬ�������Ϻ����˹�������ҵЭ�������Ϻ��˹�����ʵ���ҡ��Ϻ��ٸ۾��÷�չ(����)����˾������ԭ�ӿ�Դ���������ġ�2024ȫ�����ȷ��ᡱ������2024��3��23����24�վٰ졣