��������������ʽ���ѧϰģ�͵ķ��ٷ�չ����Ȼ���Դ���(NLP)�ͼ�����Ӿ�(CV)�Ѿ������˸����Ե�ת�䣬���мලѵ����ר��ģ�ͣ�ת��Ϊֻ��������ȷָ�������ɸ��������ͨ��ģ�͡�
�����������������ı�������(TTS)����������ת��Ҳ���ڷ�����ģ���ܹ�������ǧСʱ�����ݣ�ʹ�ϳɽ��Խ��Խ�ӽ�����������
�����������һ���о��У�����ѷ��ʽ�Ƴ��� BASE TTS���� TTS ģ�͵IJ�����ģ��������ǰ��δ�е� 10 �ڼ���

�������ı��⣺BASE TTS: Lessons from building a billion-parameter Text-to-Speech model on 100K hours of data
�����������ӣ�https://arxiv.org/pdf/2402.08093.pdf
����BASE TTS ��һ�������ԡ���˵���˵Ĵ��� TTS(LTTS)ϵͳ����Լ 10 ��Сʱ�Ĺ����������������Ͻ�����ѵ�����ȴ�ǰ��ѵ������������� VALL-E ����һ������ LLM �ɹ������������BASE TTS �� TTS ��Ϊ��һ�� token Ԥ������⡣���ַ���ͨ�������ѵ�����ݽ��ʹ�ã���ʵ��ǿ��Ķ����ԺͶ�˵����������
�������ĵ���Ҫ���������£�
����1������� BASE TTS����������Ϊֹ���� TTS ģ�ͣ����� 10 �ڲ����������� 10 ��Сʱ������������������ɵ����ݼ��Ͻ�����ѵ���������������У�BASE TTS �ı������ڹ����� LTTS ����ģ�͡�
����2��չʾ����ν� BASE TTS ��չ����������ݼ���ģ��ģ���������Ϊ�����ı������ʵ����ɵ�������Ϊ�ˣ��о��߿������ṩ��һ����ӿ�����������Լ�������Ϊ���ģ TTS ģ���ı��������Ⱦ�����������������ı����� BASE TTS �IJ�ͬ�����ڸû��ϵı��֣������ʾ���������ݼ���ģ�Ͳ����������ӣ�����Ҳ�ڵ���������
����3������˽����� WavLM SSL ģ��֮�ϵ�������ɢ������ʾ����ּ��ֻ�������źŵ���λ��������Ϣ����Щ��ʾ�����ڻ���������������ѹ��ˮƽ�ܸ�(�� 400 ���� / ��)��������ͨ�������ٺ���ʽ�������������Ϊ�������IJ��Ρ�
�����������������ǿ�������ϸ�ڡ�
����BASE TTS ģ��
��������ڵ�������ģ�������ƣ��о��߲����˻��� LLM �ķ��������� TTS �����ı������뵽���� Transformer ���Իع�ģ�ͣ���ģ�Ϳ�Ԥ����ɢ��Ƶ��ʾ(��Ϊ��������)����ͨ�������Բ�;�������ɵĵ���ѵ���Ľ����������ǽ���Ϊ���Ρ�
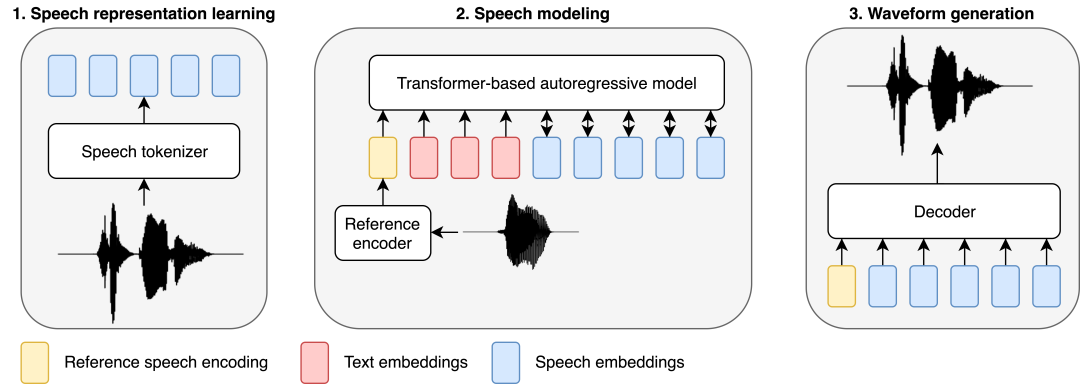
����BASE TTS ��Ƶ�Ŀ����ģ���ı� token �����Ϸֲ���Ȼ������ɢ��������ʾ���о��߳�֮Ϊ�������롣ͨ����Ƶ�������������������ɢ������Ƶĺ��ģ���Ϊ��������ֱ��Ӧ��Ϊ LLM �����ķ������� LLM ���� LTTS �����о��ɹ��Ļ�����������˵���о���ʹ�þ��н�����ѵ��Ŀ��Ľ����Իع� Transformer ������������н�ģ�����ܼ�����һĿ����Բ��������������ĸ��Ӹ��ʷֲ����Ӷ����������� TTS ϵͳ�г��ֵĹ���ƽ�����⡣��Ϊһ����ʽ����ģ�ͣ�һ�����㹻���������ѵ�����㹻��ı��壬BASE TTS ��������Ⱦ����Ҳ�����ʵķ�Ծ��
������ɢ���Ա�ʾ
������ɢ��ʾ���� LLM ȡ�óɹ��Ļ���������������ʶ���������Ϣ�ḻ�ı�ʾ�������ı�����ô���ԣ���ǰ��̽��Ҳ���١����� BASE TTS���о������ȳ���ʹ�� VQ-VAE ����(�� 2.2.1 ��)���û������Զ��������ܹ���ͨ����ɢƿ���ع� mel Ƶ��ͼ��VQ-VAE �ѳ�Ϊ������ͼ������ijɹ���������������Ϊ TTS �Ľ�ģ��Ԫ��
�����о���������һ��ͨ������ WavLM ����������ѧϰ������ʾ���·���(�� 2.2.2 ��)�������ַ����У��о��߽��� WavLM SSL ģ������ȡ��������ɢ�������ؽ� mel Ƶ��ͼ���о���Ӧ���˶������ʧ�������ٽ�˵���˵ķ��룬��ʹ���ֽڶԱ���(BPE��Byte-Pair Encoding)ѹ�����ɵ��������룬�Լ������г��ȣ��Ӷ�ʹ���ܹ�ʹ�� Transformer �Խϳ�����Ƶ���н�ģ��
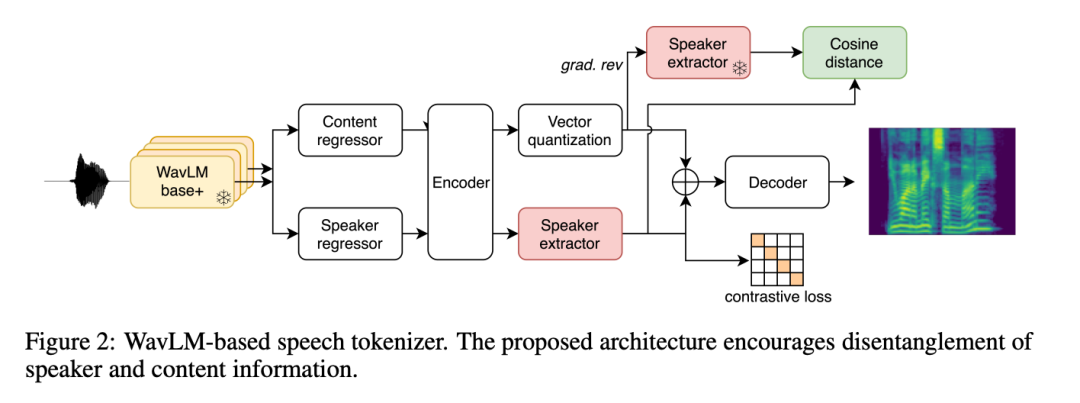
���������е���Ƶ���������ȣ������ֱ�ʾ����������ѹ��(�ֱ�Ϊ 325 bits/s �� 400 bits/s)����ʵ�ָ���Ч���Իع齨ģ����������ѹ��ˮƽ����������Ŀ����ȥ�����������п��ڽ���������ؽ�����Ϣ(˵���ˡ���Ƶ������)����ȷ�����������������Ҫ���ڱ���������������Ϣ��
�����Իع�������ģ(SpeechGPT)
�����о���ѵ����һ�� GPT-2 �ܹ����Իع�ģ�͡�SpeechGPT��������Ԥ�����ı��Ͳο�����Ϊ�������������롣�ο���������������ͬһ˵�������ѡ�����䣬����䱻����Ϊ�̶���С��Ƕ�롣�ο�����Ƕ�롢�ı����������뱻������һ�����У���������һ������ Transformer ���Իع�ģ�ͽ�ģ���о��߶��ı�������ʹ�õ�����λ��Ƕ��͵�����Ԥ��ͷ�����Ǵ�ͷ��ʼѵ�����Իع�ģ�ͣ��������ı�����Ԥѵ����Ϊ�˱����ı���Ϣ��ָ������������ SpeechGPT ������ѵ����Ŀ����Ԥ�����������ı����ֵ���һ�� token����� SpeechGPT �����Ǵ��ı� LM����������ʧ��ȣ��˴����ı���ʧ�����˽ϵ͵�Ȩ�ء�
������������
�������⣬�о���ָ����һ���������������뵽���ν�����(��Ϊ�����������������)�������ؽ�˵�������ݺ�¼��������Ϊ��ʹģ���߿���չ�ԣ������þ���������� LSTM �㣬���м��ʾ���н��롣�о����������ֻ��ھ����������������������Ч�ʸߣ��������ɢ�Ļ��߽�������ȣ�����ϵͳ�ĺϳ�ʱ������� 70% ���ϡ�
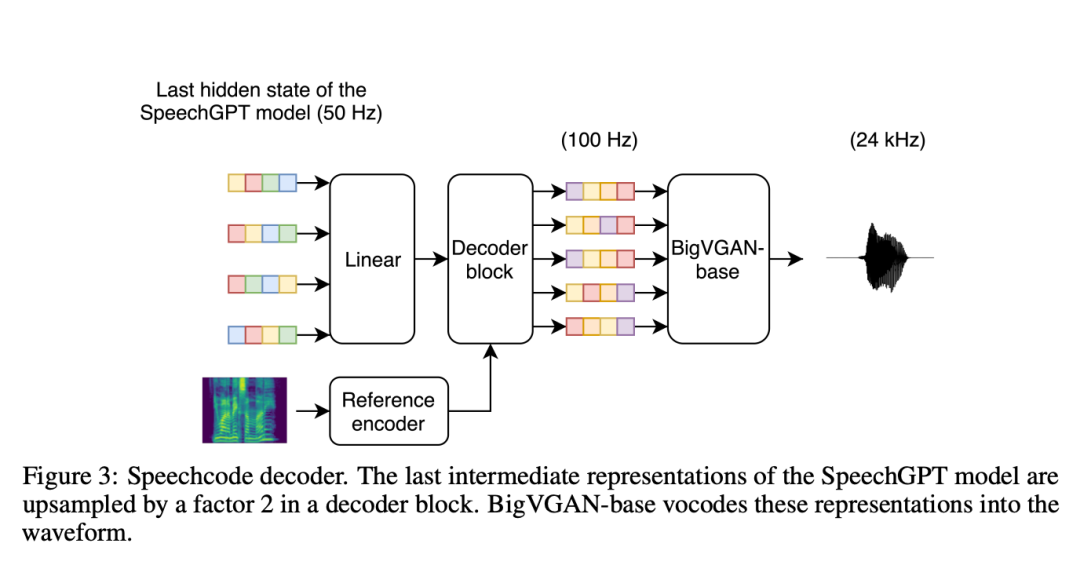
�����о���ͬʱָ����ʵ����������������������벢�����������룬�����Իع� Transformer �����һ������״̬��֮����������������Ϊ��ǰ TortoiseTTS �������ܼ���DZ�ڱ����ṩ�˱ȵ�һ����������ḻ����Ϣ����ѵ�������У��о��߽��ı���Ŀ���������ѵ���õ� SpeechGPT(��������)��Ȼ�������������״̬�Խ��������е��ڡ����� SpeechGPT ���������״̬��������������ķֶκ���ѧ��������Ҳ�Ὣ���������ض��汾�� SpeechGPT ��ϵ��������ʹʵ���ø��ӣ���Ϊ����ʹ����������ǰ�˳������һ������Ҫ�ڽ��Ĺ����м��Խ����
����ʵ������
�����о���̽�����������Ӱ��ģ����Ծ�����ս�Ե��ı���������ʵ������ɺͱ�������������� LLM ͨ�����ݺͲ������š�ӿ�֡��������ķ�ʽ���ơ�Ϊ����֤��һ�����Ƿ�ͬ�������� LTTS���о��������һ���������������� TTS ��DZ�ڵ�ӿ��������ȷ�����߸�������ս�Ե���𣺸������ʡ���С������ʡ������ԡ������š�����;䷨�����ԡ�
��������ʵ����֤�� BASE TTS �Ľṹ�������������ܺͼ������ܣ�
�������ȣ��о��߱Ƚ��˻����Զ��������ͻ��� WavLM �������������ﵽ��ģ��������
����Ȼ���о��������˶��������������ѧ��������ַ�����������ɢ�Ľ����������������������
�����������Щ�ṹ���ں��о��������� BASE TTS �����ݼ���С��ģ�Ͳ����� 3 �ֱ����е�ӿ����������������ר�ҽ�����������
�������⣬�о������������۵� MUSHRA �����Ժ�����Ȼ�ȣ��Լ��Զ��ɶ��Ⱥ�˵�������ƶȲ���������������������Դ�ı�������ģ�͵����������Ƚϡ�
����VQ-VAE �������� vs. WavLM ��������
����Ϊ��ȫ������������� token ��������������ͨ���ԣ��о��߶� 6 λ��ʽӢ��� 4 λ��������˵���˽����� MUSHRA ��������Ӣ���ƽ�� MUSHRA �������ԣ����� VQ-VAE �� WavLM ��ϵͳ��������(VQ-VAE��74.8 vs WavLM��74.7)��Ȼ������������������� WavLM ��ģ����ͳ��ѧ���������� VQ-VAE ģ��(VQ-VAE��73.3 vs WavLM��74.7)����ע�⣬Ӣ������Լռ���ݼ��� 90%���������������ݽ�ռ 2%��
������ 3 ��ʾ�˰�˵���˷���Ľ����

�������ڻ��� WavLM ��ϵͳ���������� VQ-VAE �����൱����ã�����о����ڽ�һ����ʵ����ʹ��������ʾ BASE TTS��
����������ɢ�Ľ����� vs. �������������
����������������BASE TTS ͨ������˵���������������������˻�����ɢ�Ļ��߽��������÷������������ԣ������ٶ������ 3 ����Ϊ��ȷ�����ַ������ή���������о��߶�������������������������߽������������� 4 �г��˶� 4 λ˵Ӣ��������˺� 2 λ˵����������˽��е� MUSHRA ���������

���������ʾ�������������������ѡ��������Ϊ�����ή�����������ҶԴ�����������ԣ��������������ͬʱ�ṩ������������о���ͬʱ��ʾ���������ǿ�������ģ�ͽ���������ģ�Ƕ���ģ�����ͨ��������ɢ����������
����ӿ�����������ݺ�ģ��ģ������
������ 1 �� BASE-small��BASE-medium �� BASE-large ϵͳ���������в�����
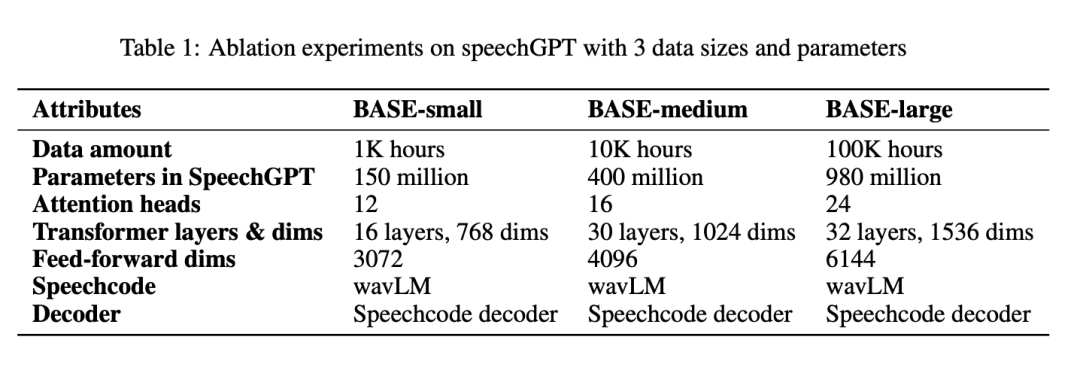
��������ϵͳ������ר���жϽ���Լ�ÿ������ƽ���÷���ͼ 4 ��ʾ��
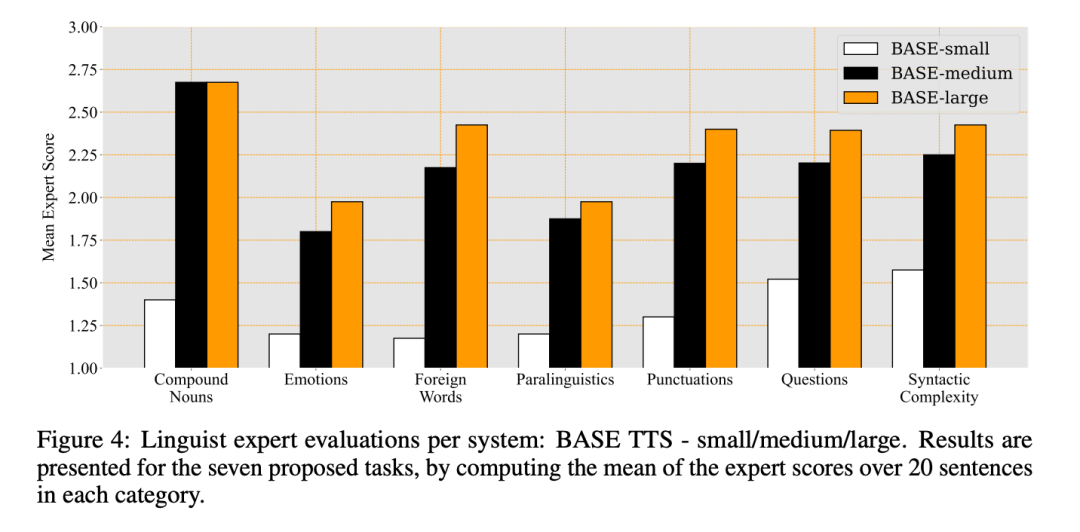
�����ڱ� 5 �� MUSHRA ����У�����ע�������Ȼ�ȴ� BASE-small �� BASE-medium �����Ը��ƣ����� BASE-medium �� BASE-large �ĸ��Ʒ��Ƚ�С��

����BASE TTS vs. ��ҵ baseline
����������˵��BASE TTS ���ɵ���������Ȼ���������ı��Ĵ�λ���٣���ο�˵���˵����������ƣ���ؽ����� 6 �ͱ� 7 ��ʾ��
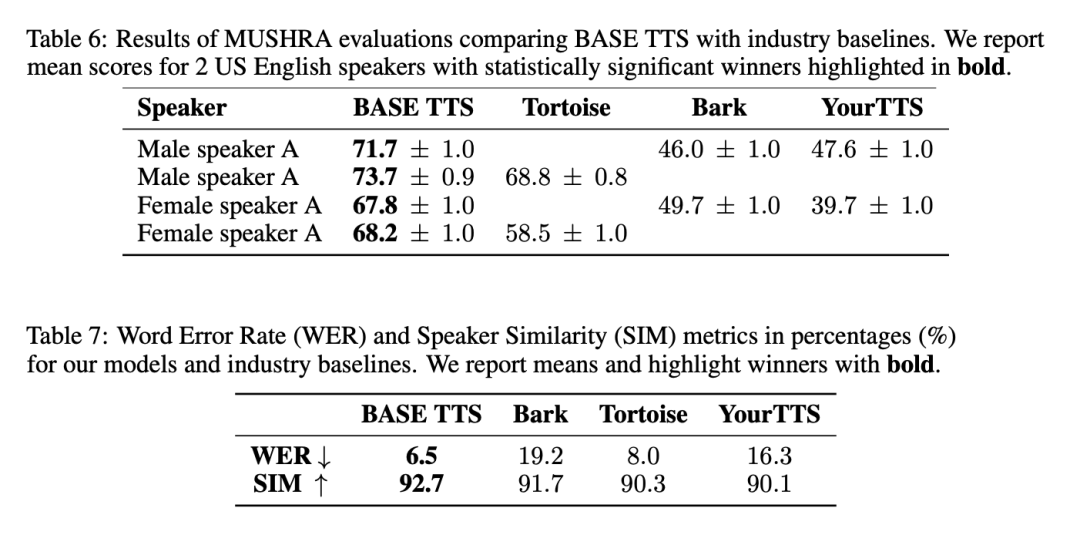

����������������������ĺϳ�Ч������
������������������ܹ�������ʽ����������������ʽ��������������һ�������Իع� SpeechGPT ���ϣ���ϵͳ�����ֽ��ӳٿɵ��� 100 ���� —— ֻ�輸������������������Բ����ɶ���������
������������ӳ��������ɢ�Ľ������γ��������Աȣ�������Ҫһ��������������������(һ����������)�������ֽ��ӳٵ���������ʱ�䡣
�������⣬�о����۲쵽������ɢ������ȣ��������������ʹ����ϵͳ�ļ���Ч������� 3 ��������������һ�������ԣ��� NVIDIA® V100 GPU ������ 1000 ������ʱ��ԼΪ 20 �����䣬����СΪ 1��ƽ�����ԣ�ʹ����ɢ��������ʮ�ڲ��� SpeechGPT ��Ҫ 69.1 �������ɺϳɣ���ʹ�������������������ͬ SpeechGPT ֻ��Ҫ 17.8 �롣
�����������ݽ����Ķ���������Ͷ�ʽ��飬������Դ���Ͷ���߾ݴ˲����������Ե���
����������...

����AI��ģ��ϵͳ�ڹ����г��Ϲ��ܺ�����Ŀǰվ���ۼ�ģ��������80���������дʵ������Ԫ���廭����ơ���Ӱ�����ͼ��ȶ�����Ӧ�ó����������������������������

9��9�գ�����Ȩ���г����л���Ӣ����(Omdia)�����ˡ��й�AI���г���1H25�����档�й�AI���г�������ռ��8%λ�е�һ��

�����Ƽ�һֱ������ͨ������λһ�塱���ݱ�����ϵ��Ϊ�й���ҵ�����ݰ�ȫ�����ݻ�������

���������������Ƴ�����ͷ��ʽ�������ֱ���ƽ����Ĥ��YH-4000�Ͷ�Ȧԭ����YH-C3000��

IDC���շ����ġ�ȫ�����ܼҾ����������豸�г����ȸ��ٱ��棬2025��ڶ����ȡ���ʾ���ϰ���ȫ�����ܼҾ����������г�����1,2��̨��ͬ������33%����ʾ��Ʒ��ǿ�����г�����

