来源:内容编译自theregister。
如果您认为人工智能网络还不够复杂,那么 Nvidia、AMD 和英特尔等公司推出的机架式架构将带来新的复杂性。
与通常使用以太网或 InfiniBand 的横向扩展网络相比,这些系统核心的纵向扩展结构通常采用专有的或至少是新兴的互连技术,可为每个加速器提供几个数量级的更高带宽。
例如,Nvidia 的第五代 NVLink 互连为每个加速器提供比当今以太网或 InfiniBand 高 9 倍到 18 倍的总带宽。
这种带宽意味着 GPU 的计算和内存可以池化,即使它们物理上分布在多个不同的服务器上。Nvidia 首席执行官黄仁勋将 GB200 NVL72 称为“一块巨型 GPU”,这可不是开玩笑。
向这些机架规模架构的转变在很大程度上受到 OpenAI 和 Meta 等模型构建者的需求的推动,它们主要针对超大规模云提供商、CoreWeave 或 Lambda 等新云运营商以及需要将其 AI 工作负载保留在本地的大型企业。
考虑到这个目标市场,这些机器的价格不菲。据The Next Platform 估计,单个 NVL72 机架的成本为 350 万美元。
需要明确的是,实现这些机架级架构的纵向扩展架构并非新鲜事物。只是到目前为止,它们很少扩展到单个节点之外,并且通常最多支持 8 个 GPU。例如,以下是 AMD 最新发布的MI350 系列系统中的纵向扩展架构。
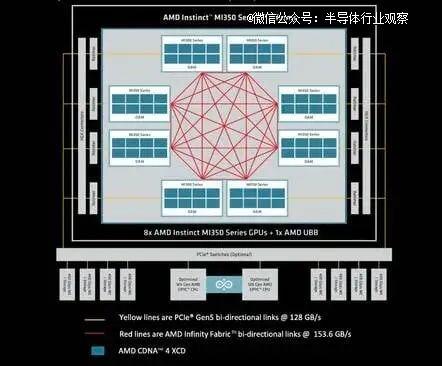
如您所见,每个芯片都以全对全拓扑结构连接其他七个芯片。
Nvidia 的 HGX 设计沿用了其四 GPU *** 系统的基本模板,但为其更常见的八个 GPU 节点增加了四个 NVLink 交换机。虽然 Nvidia表示这些交换机的好处是可以缩短通信时间,但也增加了复杂性。
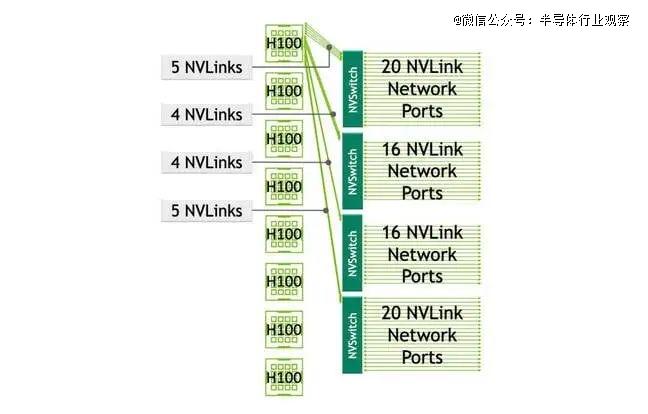
随着向机架规模的转变,同样的基本拓扑结构只是简单地扩大了规模——至少对于 Nvidia 的 NVL 系统而言是如此。对于 AMD 来说,全网状网络根本不够用,交换机变得不可避免。
01
深入探究 Nvidia 的 NVL72 扩展架构
我们稍后会深入探讨 House of Zen 即将推出的 Helios 机架,但首先我们先来看看 Nvidia 的 NVL72。由于它上市时间较短,我们对它了解得比较多。
简单回顾一下,该机架式系统拥有72 个 Blackwell GPU,分布在 18 个计算节点上。所有这些 GPU 都通过 18 个 7.2TB/s 的 NVLink 5 交换芯片连接,这些芯片成对部署在 9 个刀片服务器上。
据我们了解,每个交换机ASIC都拥有72个端口,每个端口的双向带宽为800Gbps或100GB/s。与此同时,Nvidia的Blackwell GPU拥有1.8TB/s的总带宽,分布在18个端口上——机架上的每个交换机一个端口。最终的拓扑结构看起来有点像这样:

这种高速全互连结构意味着机架中的任何 GPU 都可以访问另一个 GPU 的内存。
02
为什么要扩大规模?
据 Nvidia 称,这些海量计算域可显著提升 GPU 的运行效率。对于 AI 训练工作负载,这家 GPU 巨头估计其 GB200 NVL72 系统的速度比同等数量的 *** 系统快 4 倍,尽管在相同精度下,组件芯片的性能仅高出 2.5 倍。
同时,对于推理,Nvidia表示其机架规模配置的速度提高了 30 倍——部分原因是可以采用不同程度的数据、管道、张量和专家并行性来利用所有内存带宽,即使模型不一定受益于所有内存容量或计算。
话虽如此,Nvidia 基于 Grace-Blackwell 的机架中 VRAM 为 13.5TB 到 20TB,AMD 即将推出的 Helios 机架中 VRAM 为 30TB 左右,这些系统显然是为服务于像 Meta(显然已延迟)两万亿参数的 Llama 4 Behemoth 这样的超大模型而设计的,它将需要 4TB 内存才能在 BF16 上运行。
不仅模型越来越大,上下文窗口(可以将其视为 LLM 的短期记忆)也越来越大。例如,Meta 的 Llama 4 Scout 拥有 1090 亿个参数,并不算特别大——在 BF16 级别上运行时仅需要 218GB 的 GPU 内存。然而,其 1000 万个 token 的上下文窗口则需要数倍于此的内存,尤其是在批量大小较大的情况下。
03
推测 AMD 首 款扩展系统 Helios
毫无疑问,这就是为什么 AMD 也在其 MI400 系列加速器中采用了机架式架构。
在本月初的 Advancing AI 大会上,AMD发布了Helios 参考设计。简而言之,该系统与 Nvidia 的 NVL72 非常相似,将于明年上市,配备 72 个 MI400 系列加速器、18 个 EPYC Venice CPU 以及 AMD 的 Pensando Vulcano NIC。
关于该系统的细节仍然很少,但我们知道它的扩展结构将提供 260TB/s 的总带宽,并将通过以太网传输新兴的 UALink。
如果您还不熟悉,新兴的 Ultra Accelerator Link 标准是 NVLink 的开放替代方案,适用于扩展网络。Ultra Accelerator Link 联盟最近于 4 月发布了其首 个规范。
Helios 每块 GPU 的双向带宽约为 3.6TB/s,这将使其与 Nvidia 第 一代 Vera-Rubin 机架式系统(也将于明年推出)相媲美。至于 AMD 打算如何实现这一目标,我们只能猜测——我们也这么做了。

根据我们在 AMD 主题演讲中看到的内容,该系统机架似乎配备了五个交换刀片,每个刀片上似乎有两块 ASIC。由于每个机架配备了 72 块 GPU,这种配置让我们感觉有些奇怪。
最简单的解释是,尽管有 5 个交换刀片,但实际上只有 9 个交换 ASIC。要实现这一点,每个交换芯片需要 144 个 800Gbps 端口。这对于以太网来说略显不寻常,但与 Nvidia 在其 NVLink 5 交换机上的做法相差无几,尽管 Nvidia 使用的 ASIC 数量是 NVLink 5 的两倍,带宽却只有 NVLink 5 的一半。
其结果将是与 Nvidia 的 NVL72 非常相似的拓扑结构。

棘手的是,至少据我们所知,目前还没有能够提供这种带宽水平的交换机ASIC。几周前我们深入研究过的博通Tomahawk 6,其性能最接近,拥有多达128个800Gbps端口和102.4Tbps的总带宽。
需要说明的是,我们不知道 AMD 是否在 Helios 中使用了 Broadcom——它恰好是少数几个公开披露的非 Nvidia 102.4Tbps 交换机之一。
但即使 Helios 塞进了 10 颗这样的芯片,你仍然需要另外 16 个 800Gbps 以太网端口才能达到 AMD 宣称的 260TB/s 带宽。这到底是怎么回事呢?
我们猜测 Helios 使用的拓扑结构与 Nvidia 的 NVL72 不同。在 Nvidia 的机架式架构中,GPU 通过 NVLink 交换机相互连接。
然而,看起来 AMD 的 Helios 计算刀片将保留 MI300 系列的芯片到芯片网格,尽管有三个网格链接将每个 GPU 连接到其他三个。
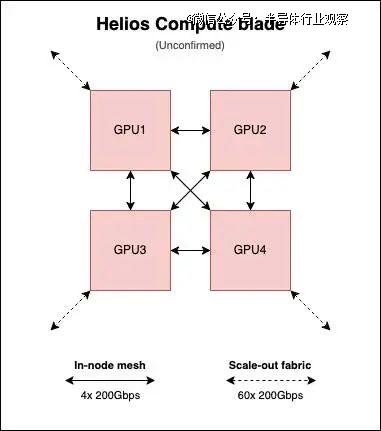
当然,这都只是猜测,但数字确实相当吻合。
根据我们的估算,每个 GPU 为节点内网格分配 600GB/s(12 条 200Gbps 链路)的双向带宽,并为扩展网络分配约 3TB/s(60 条 200Gbps 链路)的带宽。也就是说,每个交换刀片的带宽约为 600GB/s。
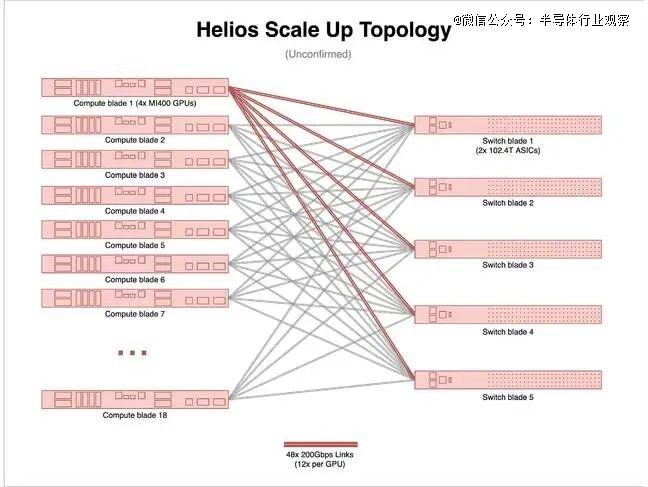
如果您觉得端口数量太多,我们预计每个计算刀片将聚合成大约 60 个 800Gbps 端口,甚至可能 30 个 1.6Tbps 端口。这有点类似于英特尔对其Gaudi3 系统的做法。据我们了解,实际布线将集成到盲插式背板中,就像 Nvidia 的 NVL72 系统一样。所以,如果您之前还在为手动连接机架网络而烦恼,现在您可以放心了。
我们可以看到这种方法的一些好处。如果我们的预测正确,那么每个 Helios 计算刀片都可以独立运行。与此同时,Nvidia 有一个单独的 SKU,名为 GB200 NVL4,专门针对 HPC 应用,它将四个 Blackwell GPU 连接在一起,类似于上图,但不支持使用 NVLink 进行扩展。
但同样,我们无法保证这就是 AMD 正在做的事情——这只是我们最 好的猜测。
04
扩大规模并不意味着停止扩大规模
您可能会认为,AMD 和 Nvidia 的机架式架构所支持的更大的计算域意味着以太网、InfiniBand 或 OmniPath — — 是的,它们回来了! — — 将退居次要地位。
实际上,这些可扩展网络无法扩展到机架之外。Nvidia 的 NVL72 和 AMD 的 Helios 等系统中使用的铜质跨接电缆根本无法达到那么远。
正如我们之前所探讨的,硅光子技术有潜力改变这一现状,但该技术在集成方面也面临着自身的障碍。我们认为,Nvidia 并非出于自身意愿而规划 600kW 机架的发展路线,而是因为它预计这些规模化网络摆脱机架束缚所需的光子技术将无法及时成熟。
因此,如果您需要超过 72 个 GPU(如果您正在进行任何类型的训练,那肯定需要),您仍然需要一个横向扩展架构。实际上,您需要两个。一个用于协调后端的计算,另一个用于前端的数据提取。
机架规模似乎也没有减少所需的横向扩展带宽。至少对于其 NVL72,Nvidia 本代产品仍坚持 1:1 的 NIC 与 GPU 比例。通常,每个刀片还会配备另外两个 NIC 或数据处理单元 (DPU) 端口,用于传统的前端网络将数据移入和移出存储等等。
这对于训练来说很有意义,但如果你的工作负载可以容纳在单个 72 GPU 的计算和内存域中,那么对于推理来说可能并非绝 对必要。剧透:除非你运行的是某个庞大的专有模型,且其细节尚不清楚,否则你很可能可以做到。
好消息是,我们将在未来 6 到 12 个月内看到一些高基数开关(high radix switches)进入市场。
我们已经提到过博通的Tomahawk 6,它将支持从64个1.6Tbps端口到1024个100Gbps端口的各种带宽。此外,英伟达的Spectrum-X SN6810也将于明年上市,它将提供多达128个800Gbps端口,并将采用硅光技术。与此同时,英伟达的SN6800将配备512个MPO端口,每个端口速率可达800Gbps。
这些交换机大幅减少了大规模 AI 部署所需的交换机数量。要以 400Gbps 的速度连接 128,000 个 GPU 集群,大约需要 10,000 台 Quantum-2 InfiniBand 交换机。而选择 51.2Tbps 以太网交换机,则可以有效地将这一数字减半。
随着转向 102.4Tbps 交换,这个数字缩减到 2,500,如果您可以使用 200Gbps 端口,则只需要 750 个,因为基数足够大,您可以使用两层网络,而不是我们在大型 AI 训练集群中经常看到的三层胖树拓扑。
文章内容仅供阅读,不构成投资建议,请谨慎对待。投资者据此操作,风险自担。
海报生成中...

海艺AI的模型系统在国际市场上广受好评,目前站内累计模型数超过80万个,涵盖写实、二次元、插画、设计、摄影、风格化图像等多类型应用场景,基本覆盖所有主流创作风格。

奥维云网(AVC)推总数据显示,2024年1-9月明火炊具线上零售额94.2亿元,同比增加3.1%,其中抖音渠道表现优异,同比有14%的涨幅,传统电商略有下滑,同比降低2.3%。

“以前都要去窗口办,一套流程下来都要半个月了,现在方便多了!”打开“重庆公积金”微信小程序,按照提示流程提交相关材料,仅几秒钟,重庆市民曾某的账户就打进了21600元。

华硕ProArt创艺27 Pro PA279CRV显示器,凭借其优秀的性能配置和精准的色彩呈现能力,为您的创作工作带来实质性的帮助,双十一期间低至2799元,性价比很高,简直是创作者们的首选。


